Making your docs site agent-readable: llms.txt, MCP, and the .well-known files that actually matter
The full agent-discovery stack a docs site can ship — llms.txt, OpenAPI, MCP, .well-known — and how to verify each.
AI agents increasingly read your docs instead of a human. If your documentation site only emits HTML for a browser, an agent has to scrape and guess. There's a better surface — and most of it is a handful of small, standard files. Here's the full stack we ship on the OrchestKit docs site, why each piece exists, and how to verify it.
flowchart TD
A(["AI agent arrives"]) --> B["GET /llms.txt — orient in one fetch"]
B --> C{"What does it need?"}
C -->|full docs| D["/llms-full.txt"]
C -->|one page| E["append .md (or Accept: text/markdown)"]
C -->|call an API| F["/api/openapi + /.well-known/api-catalog"]
C -->|use tools| G["MCP server /api/mcp + server-card.json"]
C -->|who are you| H["JSON-LD graph: Organization + SoftwareApplication"]
F --> I["RFC 9728: anonymous = a positive signal"]
D --> Z(["clean, structured context"])
E --> Z
G --> Z
H --> Z
I --> Z
How an agent traverses the surface
1. llms.txt — the agent's table of contents
A plain-text index at /llms.txt: what the product is, its constraints, and a link map to every machine-readable resource. Keep it under ~30k chars; put the exhaustive page list in /docs/llms.txt and the full corpus in /llms-full.txt. The win: an agent gets oriented in one fetch instead of crawling.

Live output from /llms.txt
2. Markdown content negotiation
Append .md to any page URL (or send Accept: text/markdown) and return the raw Markdown. Agents get clean tokens; humans still get the rendered page.
3. An OpenAPI spec for your read APIs
Even a docs site has an API surface (search, page fetch). Publish an OpenAPI document at a predictable path so an agent can call it without reverse-engineering. Pair it with RFC 9727 — a /.well-known/api-catalog linkset that enumerates every API entry point.

RFC 9727 linkset at /.well-known/api-catalog
4. An MCP server
The Model Context Protocol lets agents call your tools natively. We expose a read-only MCP server over Streamable HTTP at /api/mcp plus a discovery server-card.json. Two tools — search docs, get a doc by id — are enough to be useful.

The MCP server card
5. The .well-known identity files
agent-card.json (A2A): declares your agent skills.
agent-skills/index.json: the Agent Skills Discovery RFC, with a SHA-256 digest per skill so a consumer can verify it.
oauth-protected-resource (RFC 9728): if your API is anonymous, say so — an empty authorization_servers is a positive signal, not an omission.

The A2A agent card
6. JSON-LD that an entity graph can reconcile
Emit a schema.org graph (Organization, SoftwareApplication, WebSite) linked by @id, with sameAs pointing at the registries that already verify you (GitHub, your package registry, Wikidata). One canonical Organization block, reused everywhere, so the graph never sees conflicting identifiers. Never fabricate an aggregateRating — surface real signals (e.g. GitHub stars as an InteractionCounter) instead.
7. Tell crawlers the truth in robots.txt
Explicitly allow the named AI crawlers you want (GPTBot, ClaudeBot, OAI-SearchBot, Google-Extended…), and emit a Content-Signal directive. Link your sitemap and a schema-map.

Named AI crawlers + Content-Signal
How to verify
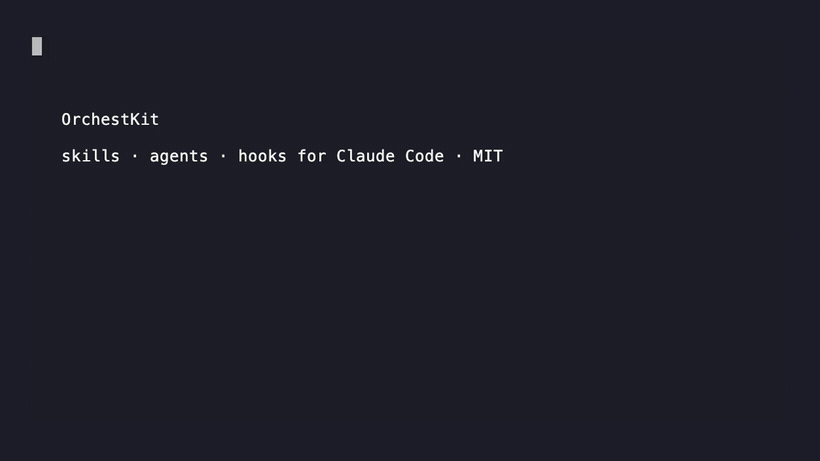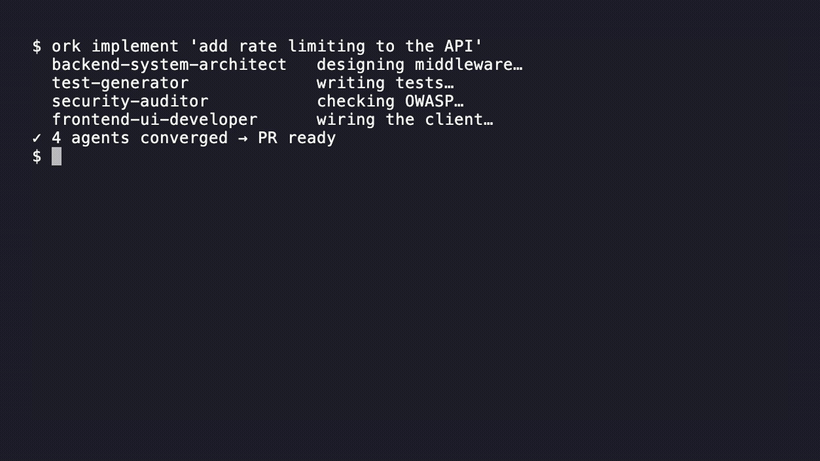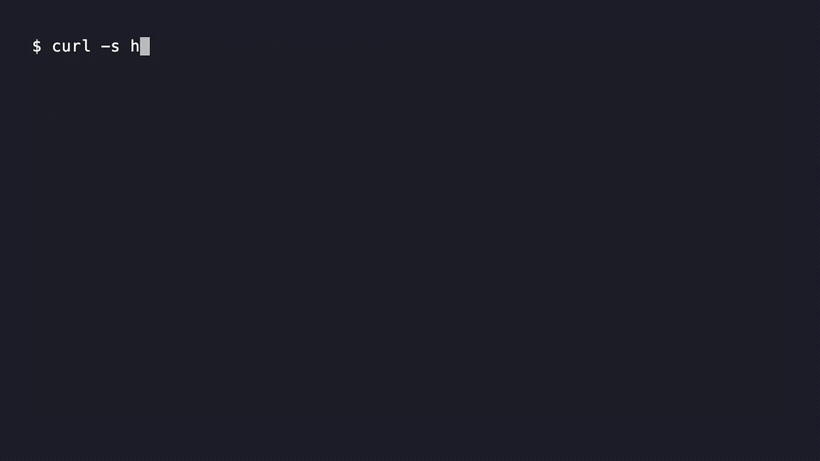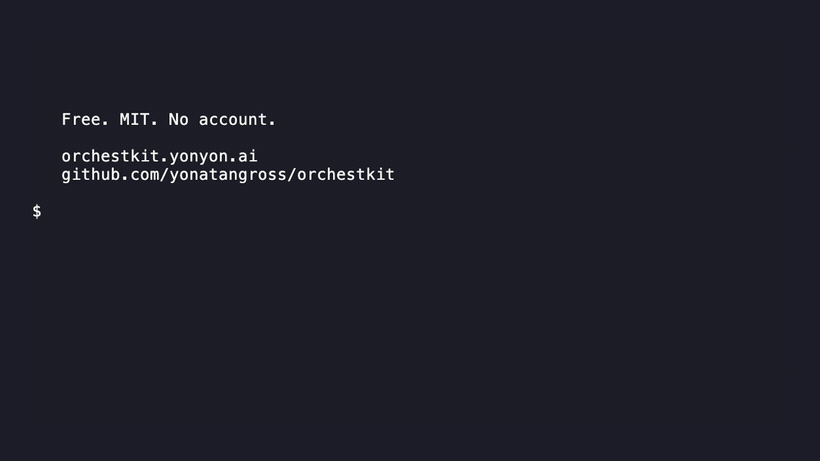
curl -s https://yoursite/llms.txt, fetch each .well-known path, and run your JSON-LD through a structured-data validator. If you build on Claude Code, the open-source OrchestKit docs site implements every item above — the source is on GitHub, MIT-licensed, and you can read the route handlers directly.
I maintain OrchestKit (a free, MIT plugin for Claude Code, 111 skills/37 agents/210 hooks). The agent-discovery surface described here is what its docs site ships today.